

SQL
Resources
What is SQL?
Pronounced through the letters instead of "sequel".
SQL means "relational database" (referring to relational database management systems).
The best thing to think about is with "excel" with a table of data.
It has a defined and a very structured schema.
SQL databases are very good at describing relations. In things like Mongo, you do not want to join collections to other collections.
PostgresQL
Enjoys a lot of market share and has some killer features.
For this course, Brian runs Postgres in a Docker container. After pulling the image, we can start a hello-postgres container:
# Start the container docker run --name hello-postgres -p 5432:5432 -e POSTGRES_PASSWORD=mysecretpassword -d --rm postgres # Attach to the container docker exec -it -u postgres hello-postgres psql
In the new Postgres program, run the following to create a database and attach:
postgres=# CREATE DATABASE message_boards; CREATE DATABASE # \c is short for `connect` postgres=# \c message_boards; You are now connected to database "message_boards" as user "postgres".
Other useful commands:
| Command | Description |
|---|---|
\c | Connect |
\d | Show Tables |
\? | Will show commands |
\h | Displays kinds of queries that you can do |
-- [input] | How to do a comment |
Creating a database
message_boards=# CREATE TABLE users ( # This is to autoincrement the IDs message_boards(# user_id INTEGER PRIMARY KEY GENERATED ALWAYS AS IDENTITY, # VARCHAR ( NUMBER ) sets a limit for the characters message_boards(# username VARCHAR ( 25 ) UNIQUE NOT NULL, message_boards(# email VARCHAR ( 50 ) UNIQUE NOT NULL, message_boards(# full_name VARCHAR ( 100 ) NOT NULL, message_boards(# last_login TIMESTAMP, message_boards(# created_on TIMESTAMP NOT NULL message_boards(# ); CREATE TABLE message_boards=# \d List of relations Schema | Name | Type | Owner --------+-------------------+----------+---------- public | users | table | postgres public | users_user_id_seq | sequence | postgres (2 rows)
Inserting into a database table
message_boards=# INSERT INTO users (username, email, full_name, created_on) VALUES ('btholt', 'foo@baz.com', 'Brian Holt', NOW()); # 0 represents OID, 1 represents success INSERT 0 1 message_boards=# SELECT * FROM users; user_id | username | email | full_name | last_login | created_on ---------+----------+-------------+------------+------------+---------------------------- 1 | btholt | foo@baz.com | Brian Holt | | 2021-02-02 07:07:17.482125 (1 row)
SELECT, LIMIT, WHERE
There is dummy data installed from the website.
After it is done, you will have a ton of data.
message_boards=# \d List of relations Schema | Name | Type | Owner --------+-----------------------------+----------+---------- public | boards | table | postgres public | boards_board_id_seq | sequence | postgres public | comments | table | postgres public | comments_comment_id_seq | sequence | postgres public | rich_content | table | postgres public | rich_content_content_id_seq | sequence | postgres public | users | table | postgres public | users_user_id_seq | sequence | postgres (8 rows) message_boards=# SELECT * FROM users LIMIT 5; user_id | username | email | full_name | last_login | created_on ---------+------------+--------------------------+-----------------+----------------------------+------ ---------------------- 1 | dpuckring0 | dpuckring0@wikimedia.org | Dicky Puckring | | 2021-01-26 07:11:40.091563 2 | ssiviour1 | ssiviour1@ow.ly | Suzanna Siviour | 2021-01-31 07:11:40.091563 | 2021-01-30 07:11:40.091563 3 | gsomerled2 | gsomerled2@auda.org.au | Geneva Somerled | | 2021-01-29 07:11:40.091563 4 | wedginton3 | wedginton3@google.com | Winny Edginton | 2021-01-28 07:11:40.091563 | 2021-01-27 07:11:40.091563 5 | mshine4 | mshine4@army.mil | Mitchael Shine | 2021-01-26 07:11:40.091563 | 2021-01-25 07:11:40.091563 (5 rows)
The WHERE clause is a straightforward projection:
message_boards=# SELECT * FROM users WHERE user_id = 1; user_id | username | email | full_name | last_login | created_on ---------+------------+--------------------------+----------------+------------+---------------------------- 1 | dpuckring0 | dpuckring0@wikimedia.org | Dicky Puckring | | 2021-01-26 07:11:40.091563 (1 row) message_boards=# SELECT username, email, user_id FROM users WHERE last_login IS NULL AND created_on < NOW() - interval '6 months' LIMIT 10; username | email | user_id -------------+------------------------+--------- ggodboltfl | ggodboltfl@hc360.com | 562 gplankfp | gplankfp@google.nl | 566 gturlefs | gturlefs@nsw.gov.au | 569 aordemannfx | aordemannfx@i2i.jp | 574 taldisfz | taldisfz@ameblo.jp | 576 cwayong2 | cwayong2@biglobe.ne.jp | 579 yraittg3 | yraittg3@msu.edu | 580 dbyrthg4 | dbyrthg4@sakura.ne.jp | 581 cmorsheadg5 | cmorsheadg5@go.com | 582 dkoppensg7 | dkoppensg7@globo.com | 584 (10 rows)
COUNT, SORT, UPDATE and DELETE
Sorted by created_on:
# Oldest message_boards=# SELECT user_id, email, created_on FROM users ORDER BY created_on LIMIT 10; user_id | email | created_on ---------+-----------------------------+---------------------------- 926 | edepp@360.cn | 2020-01-31 07:11:40.091563 929 | saspinps@wired.com | 2020-01-31 07:11:40.091563 923 | kdohertypm@mayoclinic.com | 2020-01-31 07:11:40.091563 925 | hderrickpo@wsj.com | 2020-01-31 07:11:40.091563 927 | jsappypq@sciencedaily.com | 2020-01-31 07:11:40.091563 928 | cmottepr@bbc.co.uk | 2020-01-31 07:11:40.091563 921 | akarlemanpk@blogs.com | 2020-01-31 07:11:40.091563 922 | gtivolierpl@istockphoto.com | 2020-01-31 07:11:40.091563 924 | vwindridgepn@umn.edu | 2020-01-31 07:11:40.091563 930 | bbrookespt@skyrock.com | 2020-01-31 07:11:40.091563 (10 rows) # Newest message_boards=# SELECT user_id, email, created_on FROM users ORDER BY created_on DESC LIMIT 10; user_id | email | created_on ---------+---------------------------------+---------------------------- 2 | ssiviour1@ow.ly | 2021-01-30 07:11:40.091563 3 | gsomerled2@auda.org.au | 2021-01-29 07:11:40.091563 4 | wedginton3@google.com | 2021-01-27 07:11:40.091563 1 | dpuckring0@wikimedia.org | 2021-01-26 07:11:40.091563 5 | mshine4@army.mil | 2021-01-25 07:11:40.091563 6 | marnli5@google.co.uk | 2021-01-23 07:11:40.091563 7 | wjohnston6@omniture.com | 2021-01-21 07:11:40.091563 8 | shenstone7@networksolutions.com | 2021-01-19 07:11:40.091563 9 | chuffey8@csmonitor.com | 2021-01-17 07:11:40.091563 10 | asandiland9@sun.com | 2021-01-15 07:11:40.091563 (10 rows)
COUNT can return the number:
message_boards=# SELECT COUNT(*) FROM users; count ------- 1000 (1 row) # Users that have logged in message_boards=# SELECT COUNT(last_login) FROM users; count ------- 678 (1 row)
UPDATE to change records:
message_boards=# UPDATE users SET last_login=NOW() WHERE user_id=1; UPDATE 1 # To update and return the values message_boards=# UPDATE users SET last_login=NOW() WHERE user_id=1 RETURNING *; user_id | username | email | full_name | last_login | created_on ---------+------------+--------------------------+----------------+----------------------------+---------------------------- 1 | dpuckring0 | dpuckring0@wikimedia.org | Dicky Puckring | 2021-02-02 07:23:42.988165 | 2021-01-26 07:11:40.091563 (1 row) UPDATE 1
DELETE is also fairly straight forward:
message_boards=# DELETE FROM users WHERE user_id=1000; DELETE 1
Foreign Keys
CREATE TABLE users ( user_id INTEGER PRIMARY KEY GENERATED ALWAYS AS IDENTITY, username VARCHAR ( 25 ) UNIQUE NOT NULL, email VARCHAR ( 50 ) UNIQUE NOT NULL, full_name VARCHAR ( 100 ) NOT NULL, last_login TIMESTAMP, created_on TIMESTAMP NOT NULL ); CREATE TABLE boards ( board_id INTEGER PRIMARY KEY GENERATED ALWAYS AS IDENTITY, board_name VARCHAR ( 50 ) UNIQUE NOT NULL, board_description TEXT NOT NULL ); CREATE TABLE comments ( comment_id INTEGER PRIMARY KEY GENERATED ALWAYS AS IDENTITY, -- Says to reference the `user_id` from the user table. -- ON DELETE CASCADE means if the user gets deleted, go into -- comments and delete related cascade. -- By default (ON DELETE NO ACTION), it would say "you cannot delete user". -- There is even a ON DELETE SET NULL to set that value to NULL if deleted. user_id INT REFERENCES users(user_id) ON DELETE CASCADE, board_id INT REFERENCES boards(board_id) ON DELETE CASCADE, comment TEXT NOT NULL, time TIMESTAMP );
JOIN

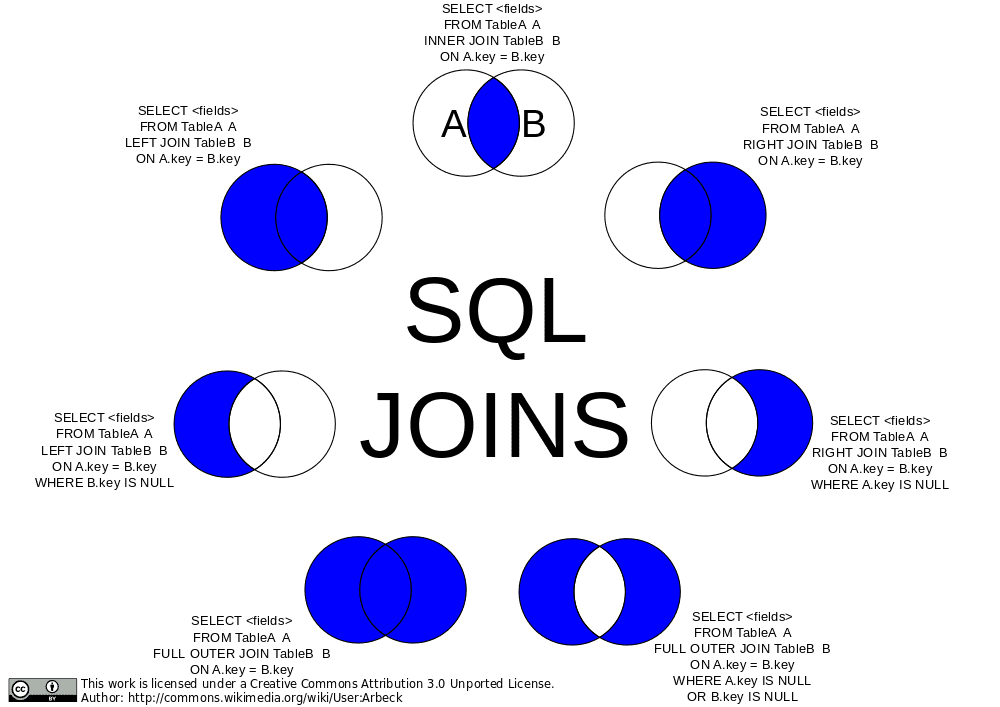
Join types
For an inner join - it allows us to match up all the keys from one table to another.
SELECT comment_id, comments.user_id, users.username, time, LEFT(comment, 20) AS preview FROM comments INNER JOIN users ON comments.user_id = users.user_id WHERE board_id = 39;
INNER JOIN which allows us to match up all the keys from one table to another. We do that in ON clause where we say userids match is where you can join together those records into one record.
A LEFT JOIN would say "if a comment has a user_id that doesn't exist, include it anyway." A RIGHT JOIN wouldn't make much sense here but it would include users even if they didn't have a comment on that board.
We can also an OUTER JOIN which would be everything that doesn't match. In our database, that would be nothing because we're guaranteed everything has match due to our constraints.
You can also do a FULL OUTER JOIN which says just include everything. If it doesn't have a match from either side, include it. If it does have a match, include it.
Another rarely useful join is the CROSS JOIN. This gives the Cartesian product of the two tables which can be enormous. A Cartesian product would be every row matched with every other row in the other table. If you have A, B, and C in one table with D and E in the other, your CROSS JOIN would be AD, AE, BD, BE, CD, an CE. If you do a cross join between two tables with 1,000 rows each, you'd get 1,000,000 records back.
Tables can also be self-joined. Imagine you have a table of employees and one of the fields is directreports which contains employeeids of employees that report the original employee. You could do a SELF JOIN to get the information for the reports.
"95% of what I do is covered by INNER and LEFT joins." - Brian
Something we can do is a NATURAL JOIN:
SELECT comment_id, comments.user_id, users.username, time, LEFT(comment, 20) AS preview FROM comments NATURAL INNER JOIN users WHERE board_id = 39;
This will work like it did above. NATURAL JOIN tells PostgreSQL "I named things the same in both tables, go ahead and match it together yourself. It is often better to be explicit what about your intent is for joins. So use cautiously and/or for neat party tricks.
Subqueries
Just be wary with this in terms of cost...
SELECT comment_id, user_id, LEFT(comment, 20) FROM comments WHERE user_id = (SELECT user_id FROM users WHERE full_name = 'Maynord Simonich');
GROUP BY
What if you were making a report and you wante to show the top ten most posted-to message boards?
SELECT boards.board_name, COUNT(*) AS comment_count FROM comments INNER JOIN boards ON boards.board_id = comments.board_id GROUP BY boards.board_name ORDER BY comment_count DESC LIMIT 10;
JSON
This course incorrectly chooses to use the
JSONdata type when it should have used theJSONBdata type. You want to choose JSONB because it stores the data in a more queryable format and more optimized for querying whereas JSON is a glorified text field.
There is a schemaless JSON type in PostgresQL. This does not exist in many SQL types. This is one place where document based databases like MongoDB really shine; their schemaless database works really well in these situations.
Here is an example of creating some JSONB values:
DROP TABLE IF EXISTS rich_content; CREATE TABLE rich_content ( content_id INTEGER PRIMARY KEY GENERATED ALWAYS AS IDENTITY, comment_id INT REFERENCES comments(comment_id) ON DELETE CASCADE, content JSONB NOT NULL ); INSERT INTO rich_content (comment_id, content) VALUES (63, '{ "type": "poll", "question": "What is your favorite color?", "options": ["blue", "red", "green", "yellow"] }'), (358, '{ "type": "video", "url": "https://youtu.be/dQw4w9WgXcQ", "dimensions": { "height": 1080, "width": 1920 }}'), (358, '{ "type": "poll", "question": "Is this your favorite video?", "options": ["yes", "no", "oh you"] }'), (410, '{ "type": "image", "url": "https://btholt.github.io/complete-intro-to-linux-and-the-cli/WORDMARK-Small.png", "dimensions": { "height": 400, "width": 1084 }}'), (485, '{ "type": "image", "url": "https://btholt.github.io/complete-intro-to-linux-and-the-cli/HEADER.png", "dimensions": { "height": 237 , "width": 3301 }}');
- The JSONB data type is the shining star here. This allows us to insert JSON objects to be queried later.
- PostgreSQL won't let you insert malformatted JSON so it does validate it for you.
- Notice you can have as much nesting as you want. Any valid JSON is valid here.
'We're going to use two new symbols, -> and ->>. The -> means "give me back the JSON object". The return type will be a JSON object, even if it's just a string. It's basically a black box to PostgreSQL and it treats all JSON the same, whether it's an array, object, or just a string. The ->> means "give me this back as a string."'
Here is some queriying is psql in action:
message_boards=# SELECT * FROM rich_content; content_id | comment_id | content ------------+------------+---------------------------------------------------------------------------------------------------------------------------------------------- ------------- 1 | 63 | {"type": "poll", "options": ["blue", "red", "green", "yellow"], "question": "What is your favorite color?"} 2 | 358 | {"url": "https://youtu.be/dQw4w9WgXcQ", "type": "video", "dimensions": {"width": 1920, "height": 1080}} 3 | 358 | {"type": "poll", "options": ["yes", "no", "oh you"], "question": "Is this your favorite video?"} 4 | 410 | {"url": "https://btholt.github.io/complete-intro-to-linux-and-the-cli/WORDMARK-Small.png", "type": "image", "dimensions": {"width": 1084, "height": 400}} 5 | 485 | {"url": "https://btholt.github.io/complete-intro-to-linux-and-the-cli/HEADER.png", "type": "image", "dimensions": {"width": 3301, "height": 237}} (5 rows) message_boards=# SELECT content -> 'type' FROM rich_content; ?column? ---------- "poll" "video" "poll" "image" "image" (5 rows) -- Ensure to use actual content message_boards=# SELECT content -> 'type' AS content_type FROM rich_content; content_type -------------- "poll" "video" "poll" "image" "image" (5 rows) -- You can "cast" to be enable to use operations of a particular data type message_boards=# SELECT DISTINCT CAST(content -> 'type' AS TEXT) AS content_type FROM rich_content; content_type -------------- "image" "poll" "video" (3 rows) -- We can cast immediately here to a string with ->> message_boards=# SELECT DISTINCT content ->> 'type' AS content_type FROM rich_content; content_type -------------- video poll image (3 rows)
For going deeper into the JSON object:
SELECT content -> 'dimensions' ->> 'height' AS height, content -> 'dimensions' ->> 'width' AS width, comment_id FROM rich_content WHERE content -> 'dimensions' IS NOT NULL;
Indexes in PostgresSQL
Performance is always a concern.
You can put EXPLAIN in front of any query and it will given you an overview about how the query will run:
message_boards=# EXPLAIN SELECT comment_id, user_id, time, LEFT(comment, 20) FROM comments WHERE board_id = 39 ORDER BY time DESC LIMIT 40; QUERY PLAN ----------------------------------------------------------------------- Limit (cost=65.75..65.78 rows=12 width=48) -> Sort (cost=65.75..65.78 rows=12 width=48) Sort Key: "time" DESC -> Seq Scan on comments (cost=0.00..65.53 rows=12 width=48) Filter: (board_id = 39) (5 rows)
65 is not a great search and we are seeing the sequential scans that we are not hoping to see.
In this scenario, given the access pattern, we will want to add an index on board_id. We can create indexes with CREATE INDEX [idx name] ON <table> (<attribute>)
message_boards=# CREATE INDEX comments_board_id_idx ON comments (board_id); CREATE INDEX message_boards=# EXPLAIN SELECT comment_id, user_id, time, LEFT(comment, 20) FROM comments WHERE board_id = 39 ORDER BY time DESC LIMIT 40; QUERY PLAN ------------------------------------------------------------------------------------------------- Limit (cost=33.73..33.76 rows=12 width=48) -> Sort (cost=33.73..33.76 rows=12 width=48) Sort Key: "time" DESC -> Bitmap Heap Scan on comments (cost=4.37..33.51 rows=12 width=48) Recheck Cond: (board_id = 39) -> Bitmap Index Scan on comments_board_id_idx (cost=0.00..4.37 rows=12 width=0) Index Cond: (board_id = 39) (7 rows)
The cost is now much better!
You can drop the index with DROP INDEX [idx_name];.
To create a unique index, we could use CREATE UNIQUE INDEX username_idx on users(username);. This looks similar to a UNIQUE constraint on an attribute.
message_boards=# CREATE UNIQUE INDEX username_idx on users(username); CREATE INDEX message_boards=# SELECT username FROM users WHERE user_id = 10; username ------------- asandiland9 (1 row)